

 Поделиться
Поделиться
«Яндекс» обновил технологию фотоперевода: новая версия поможет легко читать тексты с картинок на десятках языков
«Яндекс» представил новую версию технологии перевода текста на фото и изображениях на базе нейросетей. Компания одной из первых в мире применила большую языковую модель, чтобы переводить картинки с учетом контекста. Технология поможет, например, в поездке, если нужно быстро перевести меню в ресторане, или в работе, чтобы разобраться в нюансах технической документации на иностранном языке. Кроме того, «Яндекс» улучшил визуализацию перевода — текст теперь легче читается и больше похож на оригинальную верстку. Обновление уже доступно в «Переводчике» и «Браузере», а позже появится и в «Умной камере».
Модель семейства YandexGPT понимает стиль оригинального текста и может сохранить игру слов, например, на фотографиях рекламных слоганов или газетных заголовков. Новая технология на базе нейросетей позволила подбирать более точные формулировки во фразах с несколькими значениями и не переводить выражения дословно. За счет этого выросло как качество перевода простых текстов, таких как состав косметической продукции, так и сложных — публицистических статей, энциклопедий и инструкций. Перевод на основе большой языковой модели работает для изображений с текстом на английском.
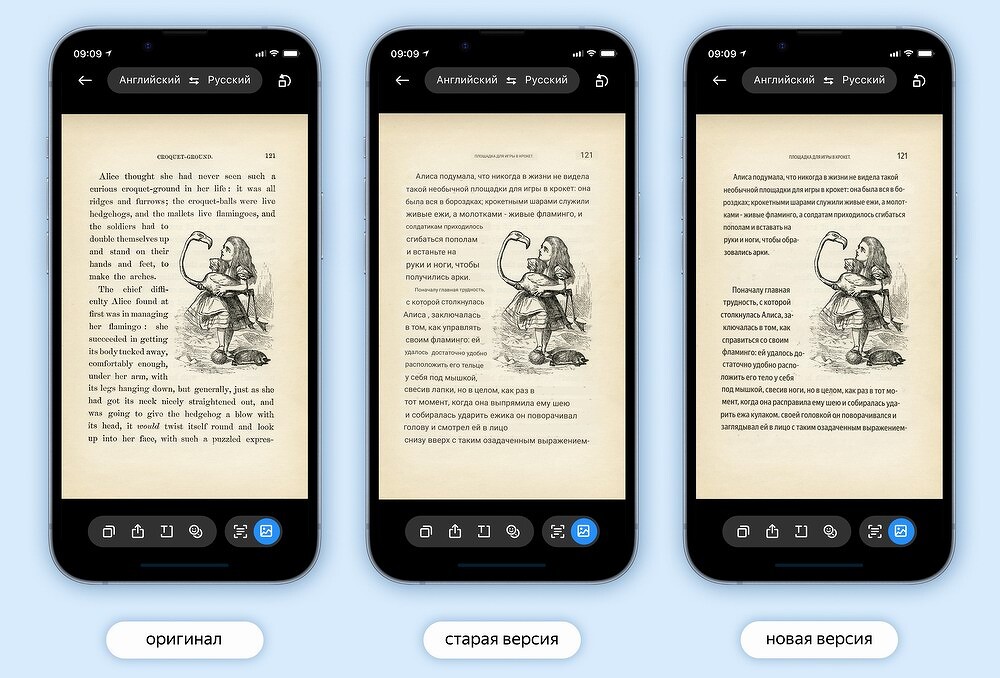
Чтобы пользователю было удобно читать перевод текста на картинках, «Яндекс» улучшил его визуализацию для нескольких десятков языков. Технология стирает оригинальный текст с изображения и располагает переведенный поверх него: алгоритмы подбирают шрифт, размер и цвет букв, а также убирают различные артефакты таким образом, чтобы переведенные изображения выглядели наиболее естественно. Кроме того, текст получается контрастным, за счет чего его читать даже легче, чем оригинал. Технология распознает переносы слов и может понять их значение, даже если в кадр попала только часть.
Для перевода текста на изображениях разработчики «Яндекса» создали отдельную модель семейства YandexGPT, адаптированную под задачи перевода с английского на русский. Ее обучали на множестве пар оригинальных и переведенных текстов. Модели показывали примеры качественных и плохих переводов, чтобы она училась подражать эталонным, избегала ошибок и не добавляла в свои тексты несуществующие детали.
Для того чтобы нейросеть могла быстро обрабатывать большое количество запросов пользователей, разработчики применили метод дистилляции, при котором от большой «учительской» модели семейства YandexGPT знания передаются к меньшей «ученической». Меньшая модель старается подражать поведению большой модели, и качество ее ответов остается на уровне «учительской» при меньших вычислительных затратах.
 Короткая ссылка
Короткая ссылка


















