Поделиться
Поделиться
В Cloudflare произошел крупный сбой из-за «кривой» попытки заблокировать фишинговую ссылку
Попытка заблокировать фишинговый ссылки на ИТ-платформе Cloudflare R2 случайно вызвала масштабный сбой, из-за которого многие сервисы Cloudflare не работали почти час. Инцидент длился около часа, в течении этого времени были полностью недоступны были Cloudflare Stream, Cloudflare Images, Cache Reserve и ряд других сервисов.
Безуспешная попытка ограничения
Попытка заблокировать фишинговый ссылки на платформе Cloudflare R2 случайно вызвала масштабный сбой, из-за него многие сервисы Cloudflare не работали почти час. Сообщение об этом событии было опубликовано в блоге компании в феврале 2025 г.
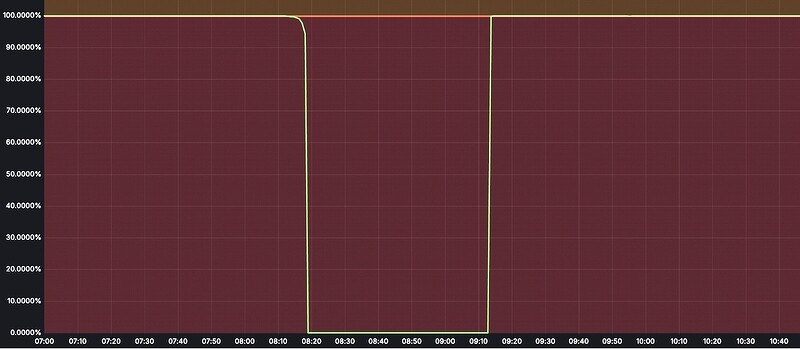
Со слов специалистов по кибербезопасности Cloudflare, хранилище R2, были недоступны в течение 59 минут 6 февраля 2025 г. Это привело к сбою всех операций с R2 на время инцидента, а также к значительным сбоям в работе ряда других сервисов Cloudflare. Включая сервисы Stream, Images, Cache Reserve, Vectorize и Log Delivery.
Облако подключений Cloudflare защищает целые корпоративные сети, помогает клиентам эффективно создавать приложения интернет-масштаба, ускоряет работу любого веб-сайта или интернет-приложения, защищает от DDoS-атак, держит хакеров на расстоянии и может помочь вам на пути к Zero Trust.

ИТ-инцидент произошел из-за человеческой ошибки и недостаточных гарантий проверки во время обычного устранения нарушений в связи с сообщением о фишинговом сайте, размещенном на R2. Действия, предпринятые в связи с жалобой, привели к отключению расширенного продукта на сайте, что привело к отключению производственной службы R2 Gateway, отвечающей за API R2. Очень важно, что этот инцидент не привел к потере или повреждению каких-либо данных, хранящихся в облаке Cloudflare.
По данным Cloudflare, в итоге инцидент длился 59 минут, и помимо самого объектного хранилища R2 он затронул и другие сервисы, включая: Stream - 100% отказ при загрузке и доставке потокового видео; Images - 100% отказ при загрузке и выгрузке изображений; Cache Reserve - 100% отказ в работе, что привело к увеличению количества запросов к источникам; Vectorize - 75% отказов для запросов, и 100% отказ для операций вставки, удаления и upsert; Log Delivery - задержки и потеря данных (до 13,6% потерь данных для связанных с R2 логов, а также до 4,5% потерь данных для несвязанных с R2 delivery job); Key Transparency Auditor - 100% отказ при операциях публикации и чтения подписи.
Косвенно пострадали и другие ИТ-сервисы, в работе которых наблюдались частичные сбои. Например: Durable Objects, в котором количество ошибок увеличилось на 0,09% из-за повторных подключений. Cache Purge, где количество ошибок (HTTP 5xx) увеличилось на 1,8%, а задержка возросла в 10 раз. Workers & Pages для которого сбои при развертывании составили 0,002%, затронув только проекты с привязкой к R2.
По информации Cloudflare, именно из-за человеческой ошибки и недостаточных средств проверки в ИТ-инструментах администрирования служба шлюза R2 была отключена в рамках планового устранения фишинговых ссылок на платформе.
Плохая настройка защиты ИТ-систем
Ключевой контроль на уровне системы, который привел к этому инциденту, заключался в том, как в Cloudflare идентифицируют внутренние учетные записи, используемые командами. Они обычно имеют несколько учетных записей (dev, staging, prod), чтобы уменьшить радиус распространения любых изменений конфигурации или развертываний. ИТ-системы обработки злоупотреблений не были явно настроены на идентификацию этих учетных записей и блокировку действий по их отключению. Вместо того чтобы отключить конкретную конечную точку, связанную с отчетом о злоупотреблении, ИТ-система позволяла оператору (ред. по человеческой ошибке) отключить службу шлюза R2.
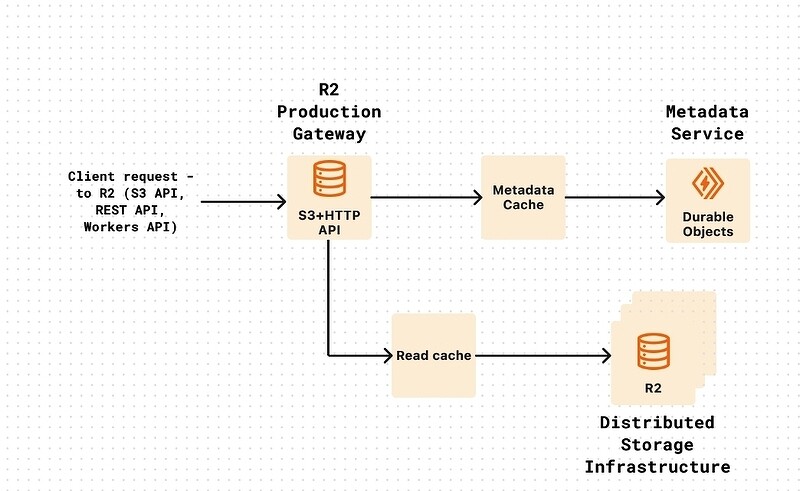
Как только программисты Cloudflare определили, что именно стало причиной сбоя в сервисах, появилась другая проблема. Устранение и восстановление было затруднено из-за отсутствия прямых элементов управления для отмены действий по отключению ИТ-продукта и необходимости привлечения операционной команды с более низким уровнем доступа, чем обычно. Это означает, что сотрудники с более низким уровнем доступа не имеют доступа к конфиденциальной информации и ресурсам, но уровни доступа на основе ролей обычно более детализированы. Затем потребовалось повторное развертывание службы R2 Gateway для восстановления маршрутизации в нашей пограничной сети.
Лишь после повторного развертывания ИТ-системы клиенты Cloudflare смогли снова подключиться к R2, а показатели ошибок для зависимых служб (включая Stream, Images, Cache Reserve и Vectorize) вернулись к нормальному уровню.
Пересмотр прав по безопасности
Разработчики Cloudflare отмечают, что причиной инцидента стали как человеческий фактор, так и отсутствие таких защитных мер, таких как валидация потенциально опасных действий. В компании уже приняли соответствующие меры.
В частности, возможность отключения ИТ-систем была удалена из интерфейса, которым пользуются специалисты Cloudflare по устранению злоупотреблений. Также после ИТ-инцидента были развернуты дополнительные защитные механизмы, реализованные в API администратора для предотвращения отключения сервисов, запущенных во внутренних учетных записях.
В настоящее время специалисты Cloudflare работает над изменением способа создания всех внутренних учетных записей (staging, dev, production) для обеспечения корректной привязки всех учетных записей к правильной организации. Это должно включать защиту от создания автономных учетных записей, чтобы избежать повторения этого или подобных инцидента в будущем.
В компании Cloudflare продолжат дальнейшие операции по ограничению доступа к действиям по отключению ИТ-продукта, выходящим за рамки рекомендованных ИТ-системой мер по устранению неполадок, для более узкой группы старших операторов.
Для специальных действий по отключению ИТ-продукта теперь требуется двухстороннее одобрение. В дальнейшем, если расследователю требуются дополнительные меры по исправлению ситуации, они должны быть представлены менеджеру или лицу, входящему в список одобренных лиц, принимающих меры по исправлению ситуации.
Расширение существующих проверок на злоупотребления, которые предотвращают случайное блокирование внутренних имен хостов, чтобы также предотвратить любые действия по отключению продуктов, связанных с внутренней учетной записью Cloudflare.
Внутренние учетные записи переводятся в новую модель «Организации» до публичного выпуска этой функции. Производственная учетная запись R2 входила в эту организацию, но механизм исправления нарушений не имел необходимых средств защиты для предотвращения действий против учетных записей в этой организации.
В Cloudflare продолжают обсуждать и анализировать дополнительные шаги и усилия, которые могут уменьшить масштаб любого системного или человеческого действия. Все сотрудники компании Cloudflare понимают, что это был серьезный ИТ-инцидент, и они с болью признают свою вину и крайне сожалеют о нем.
 Короткая ссылка
Короткая ссылка